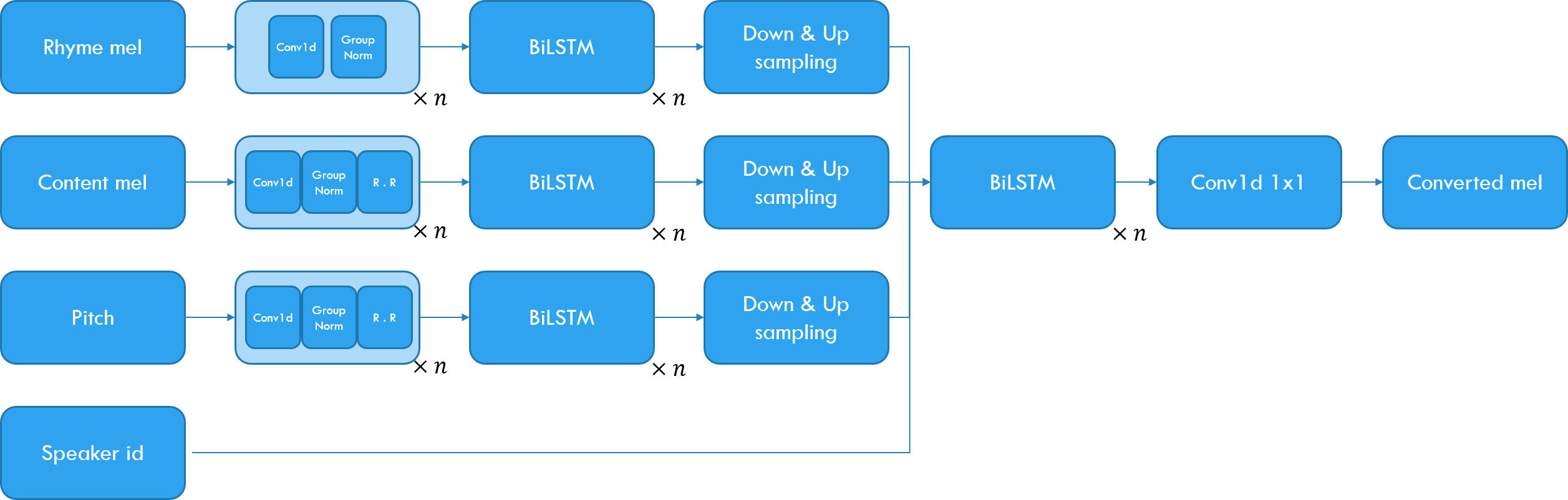
| Speaker | Category | Source |
|---|---|---|
| VCTK P243 | Consistent (Male) | |
| VCTK P240 | Consistent (Female) | |
| VCTK P232 | Trained(Male) | |
| VCTK P277 | Trained(Female) | |
| VCTK P226 | Unseen(Male) | |
| VCTK P228 | Unseen(Female) |
| Speaker | Source | Conversion | ||
|---|---|---|---|---|
| P243 | P243 (Consistent) |
|||
| P232 (Trained, male) |
||||
| P277 (Trained, female) |
||||
| P226 (Unseen, male) |
||||
| P228 (Unseen, female) |
||||
| P240 | P240 (Consistent) |
|||
| P232 (Trained, male) |
||||
| P277 (Trained, female) |
||||
| P226 (Unseen, male) |
||||
| P228 (Unseen, female) |
||||
| Speaker | Rhyme | Content | Pitch |
|---|---|---|---|
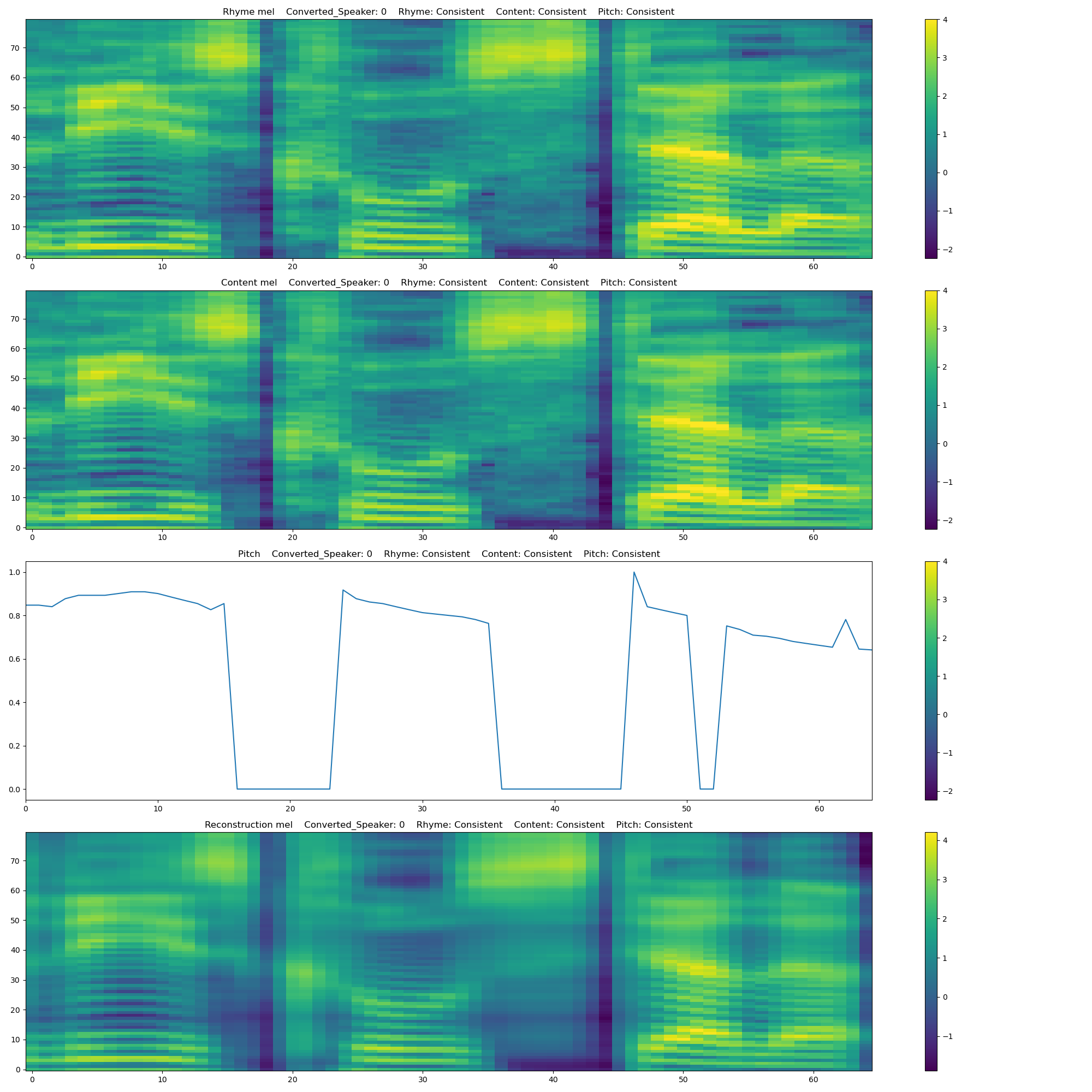 |